The line list dataset from Peru provides 8 metadata fields for each patient. These include ‘Universally unique identifiers (UUID)’ which unfortunately change through time (i.e., with every update of the dataset there are new UUIDs which do not correspond to previous days). Geographic metadata are provided and include the Department, Province & District (DEPARTAMENTO, PROVINCIA & DISTRITO) of where the case was reported. The only date provided is the date of confirmation of SARS-CoV-2 infection and the associated PCR, LFT or Serological test (no other information). Other metadata include the exact age; sex (male, female) of the patient (see table above). These fields are consistently filled out (>99% of the time) making them very useful for downstream analyses.
There were some reporting changes through time including as of June 2020 the database stopped including positive tests identified by IPRESSs (Instituciones Prestadoras de Salud – Health Service Provider Institutions) which were run for private companies to enable workers to return to work.
Further, there were some small geocoding issues which we detail below: The geographic metadata of each case (Department, Province & District) are often provided in a non-standard way in this database such that they sometimes do not exactly match the official place name.
For example, place names are abbreviated:
“SAN FRANCISCO DE ASIS DE YARUSYACAN, PASCO, PASCO” is abbreviated as
“SAN FCO DE ASIS DE YARUSYACAN, PASCO, PASCO”
By inspecting commonly occurring place name mismatches, we augmented our lookup table with a number of mispelled or abbreviated place names, to ensure more cases could be correctly geocoded and therefore added to our database.
During one recent ingestion (May 26th, 2021) 1,913,719 cases were ingested out of a total of 1,925,289. We identified one error where age validation failed (age = -79), out of the remaining 11,320 that did not ingest 2023 did not contain information about ‘FECHA_RESULTADO; and 9297 failed the geocoding lookup and were not added to the database. We also note that there are 23 cases with age >120 which were excluded.
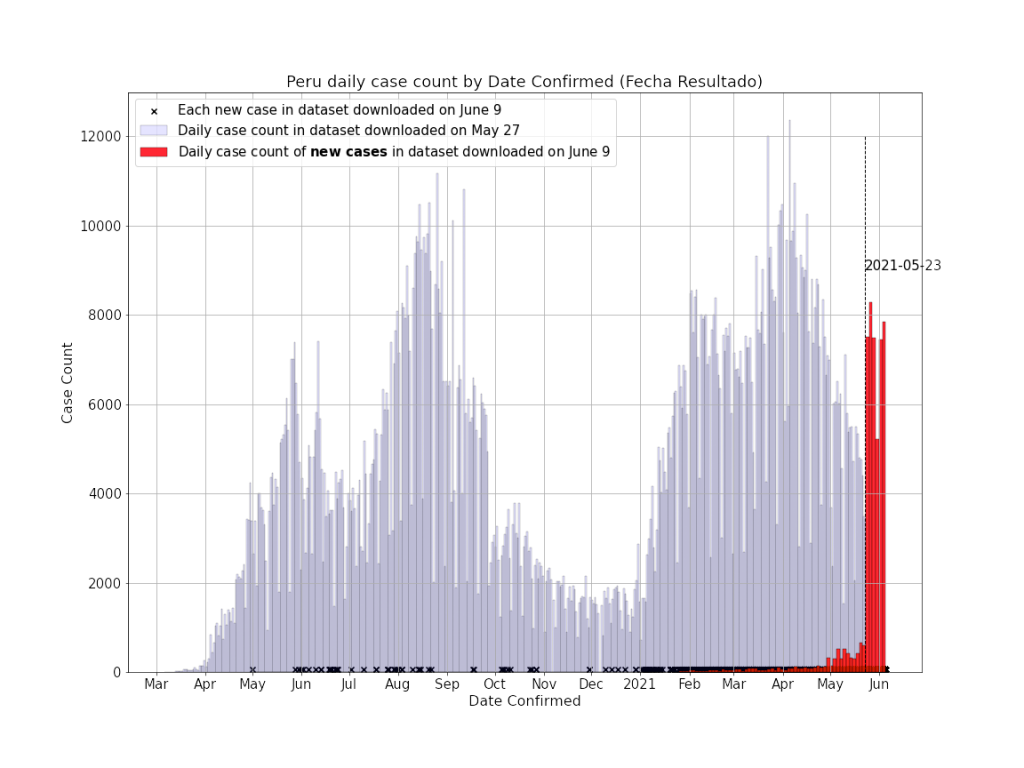
June spike in cases:
Between May 23rd and June 9th, an additional 51,315 cases were added to the database, creating a spike in the daily case rate. A small subset of these had Date Confirmed (FECHA RESULTADO) in 2020 (indicated with black crosses in the Figure below). This spike in daily cases coincides with reports of a large increase in COVID-19 related deaths counted in Peru, due to a revision in the case definition of COVID-19 related deaths (see also: https://www.bmj.com/content/373/bmj.n1442).